Introduction
Cannabis legalization is rapidly spreading throughout the United States (McGinty et al., 2017). In 2010, 27 percent of Americans lived in states with legal recreational and medical cannabis or medical cannabis only; by 2018, this figure had more than doubled to 56 percent (National Conference of State Legislatures. Marijuana Overview: Legalization, 2018; National Conference of State Legislatures. State Medical Marijuana Laws, 2019; US Census Bureau, 2018). In this rapidly evolving legal environment, cannabis use has increased. According to the National Survey on Drug Use and Health (NSDUH), national past-month cannabis use increased significantly between 2002 and 2016 among 18-to-25-year-olds (17.3 percent to 20.8 percent, P < 0.05) and adults 26 years old and older (4.0 percent to 7.2 percent, P < 0.05) (Substance Abuse and Mental Health Services Administration (SAMHSA), 2017).
Validated population-level surveys of cannabis use, such as NSDUH, primarily focus on establishing the prevalence of cannabis use alone or in combination with the use of other substances (National Survey on Drug Use and Health, 2020). For example, whereas NSDUH assesses perceived risk and availability of cannabis, it does not provide additional information on knowledge, attitudes, and beliefs (KABs) about cannabis (Center for Behavioral Health Statistics and Quality, 2017). In addition, the relationship between cannabis policies and use remains somewhat unclear, partly due to difficulty obtaining individual-level information on cannabis use combined with geographic identifiers (Centers for Disease Control and Prevention, 2020). Access to these datasets is often restricted to prevent confidentiality. As a result, the predictors of national cannabis use remain unclear.
To address the lack of national information on the relationship between KABs, cannabis policies, and cannabis use at the time, RTI International launched the National Cannabis Climate Survey (NCCS) in August 2016. The survey combined address-based (probability) and social media (nonprobability) samples to obtain information about the relationship between the cannabis legal environment (recreational and medical legalization, medical only legalization, or neither), KABs, and cannabis use behaviors among the general population and adult cannabis users.
The NCCS combined probability and nonprobability samples to balance the advantages and disadvantages of these two types of samples (Dever, 2018). Probability samples (e.g., address-based samples; ABS) provide broad coverage of the US household population (Hruska & Maresova, 2020; Poushter, 2017), result in less coverage bias than nonprobability samples (Dever, 2018), and are generally subject to very little fraud (Dewitt et al., 2018; Grey et al., 2015; Konstan et al., 2006). Nonprobability samples, such as social media samples, are efficient for accessing hard-to-reach and rare populations (Tourangeau, 2014), such as current cannabis users. However, nonprobability samples are susceptible to constantly evolving methods of fraud (Dewitt et al., 2018), such as multiple submissions of a survey by the same individual (often with varying identifying information to attempt to escape detection) (Bowen et al., 2008), manipulating answers to screen into studies (“gaming the survey”) (Dewitt et al., 2018; Grey et al., 2015), and bots (Dewitt et al., 2018), among others.
Several fraud prevention procedures (designed to prevent fraudulent completes of surveys) have been identified for social media samples, including asking participants not to complete surveys more than once or asking if they have previously completed the survey and collecting identifying information, such as e-mail addresses, IP addresses, and zip codes (Dewitt et al., 2018; Konstan et al., 2006; Nosek et al., 2002). In addition, several established fraud detection procedures exist. These procedures, which are applied to remove fraudulent completes after data collection has occurred, often include deduplication (removal of duplicate entries) and cross-validation (confirming that the participant met inclusion criteria) (Bowen et al., 2008; Dewitt et al., 2018; Grey et al., 2015; Konstan et al., 2006; Mustanski, 2001; Nosek et al., 2002).
All of these procedures, however, have limited efficacy in detecting and removing fraudulent completes(Dewitt et al., 2018). A few studies have identified additional methods of identifying fraud after data collection. These studies identified distinguishing characteristics of fraudulent responses and used these characteristics to identify potential fraudulent responses (Baker & Downes-Le Guin, 2007; Bowen et al., 2008; Dewitt et al., 2018). Generally, these techniques rely on examining one indicator of fraud at a time, usually through bivariate comparisons. However, as was the case with the NCCS, fraudulent completes can present as patterns of responses across multiple variables, resulting in the need for more sophisticated fraud detection methods than bivariate analyses. To address this issue, we developed a fraud prediction model to calculate the probability that each response was fraudulent based on patterns of responses to key variables. To our knowledge, this is the first publication to use multivariable modeling to calculate the probability of fraud in a social media sample.
This manuscript describes the fraud model, the weighting scheme that we used to calibrate multiple probability and nonprobability samples after eliminating fraudulent responses, and the validation of the survey results. The fraud model presented in this manuscript has two advantages over existing methods of identifying characteristics of fraudulent responses: it combines patterns of responses for multiple variables to determine fraud, and it produces a continuous probability that researchers can use to carefully evaluate the likelihood of fraud for each participant. The fraud model can be applied to existing and future datasets when traditional fraud prevention and detection methods are insufficient. Because of rapidly evolving (and increasingly sophisticated) methods of committing fraud on social media (Dewitt et al., 2018), multivariable methods of identifying fraud are and will continue to be needed.
Materials and Methods
Sample
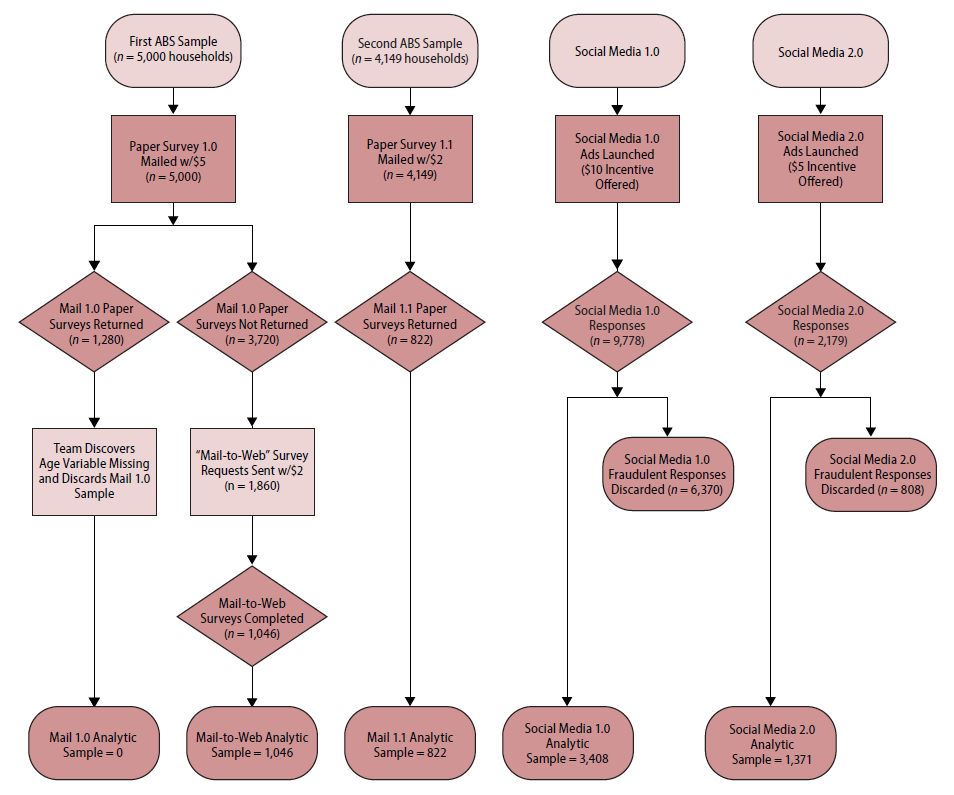
Between August 2016 and May 2017, we collected data for the NCCS through two ABS household (probability) samples and two social media (nonprobability) convenience samples. The purpose of the survey was to compare cannabis-related KABs across states with three different cannabis legal environments: states with recreational and medical cannabis laws, states with medical cannabis laws only, and states with neither medical nor recreational cannabis laws. We sampled an approximately equal number of addresses from each legal environment by using stratified sampling methods for the ABS samples and quotas for the social media samples. Inclusion and exclusion criteria were identical for all modes of data collection except when noted in the following sections. Participants had to be 18 years of age or older and live in the continental United States. The RTI International Institutional Review Board approved all procedures.
ABS Samples
We obtained two ABS samples (Figure 1) from RTI International’s in-house ABS frame (http://abs.rti.org), which is sourced from the US Postal Service Computerized Delivery Sequence file (CDS). The CDS, which is updated monthly, contains all mail delivery points in the United States, and as is the case with most ABS samples, offers high coverage of the household population for mailed surveys (American Association for Public Opinion Research. Address-Based Sampling, 2016).

Mail 1.0 and Mail-to-Web Samples
The first ABS sample (“Mail 1.0”) included 5,000 addresses (Table 1). We mailed these households a paper survey with a $5 incentive; 1,280 participants returned the mail survey. Of the 3,720 households that did not return the paper survey, we sent half of these households (n = 1,860) instructions for accessing the survey by web and a $2 incentive. We received 1,046 “Mail-to-Web” completes. The total number of responses to the Mail 1.0/Mail-to-Web recruitment was 2,326 out of the original 5,000 households sampled, yielding a response rate of 46.5%. Upon receiving the completed Mail 1.0 responses, we found that the age variable was missing from the survey, so the resulting data was discarded. The Mail-to-Web data was not affected by this issue.
Mail 1.1 Sample
We used a second ABS mail sample (“Mail 1.1”) to replace the faulty data from the Mail 1.0 survey. Excluding all households in the first ABS sample, we drew a new sample of 4,149 households. We mailed paper surveys to 4,149 households and received 822 completed surveys (19.8 percent response rate). To reduce the cost of the second mail survey, we lowered the initial incentive from $5 to $2; there was no additional incentive included with reminder materials.
Social Media Surveys
Next, we performed two rounds of social media data collection to supplement the number of current adult cannabis users in the ABS sample. For both rounds, we used paid social media ads to target participants and delivered incentives via Amazon gift cards. The ads did not reveal the subject matter of the survey. Because of our interest in policy analyses, we set quotas to recruit an approximately equal number of participants from states with recreational and medical cannabis legalization, medical cannabis only legalization, or neither type of legalization based on the effective dates of state recreational and medical cannabis laws in July of 2016.
Social Media Fraud Prevention
When developing the social media surveys, we included fraud prevention measures that were established in the literature at the time (Bowen et al., 2008; Grey et al., 2015; Nosek et al., 2002), including obscuring the purpose of the study through the use of distractor questions in the screener, collecting IP addresses, recording timestamps, instructing participants not to complete the survey multiple times (and noting that incentives would be withheld as a result), collecting e-mail address and state of residence, and asking questions assessing inclusion criteria in both the screener and body of the survey. Additional fraud prevention measures applied to the second social media sample are described in subsequent sections.
Social Media 1.0
For the first round of social media data collection (SM 1.0), we used paid advertisements on Facebook to recruit participants, and the incentive was $10. We received a large quantity of responses at odd hours (2:00 to 4:00 a.m. US Central time) from IP addresses outside of the United States and found evidence of link sharing on third-party websites. We collected 9,778 SM 1.0 responses.
Social Media 2.0
We conducted a second round of social media data collection (SM 2.0) to replace suspected fraudulent responses in SM 1.0. We used paid advertisements on Instagram only (to decrease the likelihood of overlap across the two social media samples) and targeted states with low completion rates for SM 1.0. We screened out participants who said that they had completed an RTI survey in the past 3 months to prevent individuals from completing both social media surveys. We collected 2,179 SM 2.0 responses.
Based on lessons learned from SM 1.0, SM 2.0 included additional fraud prevention measures, including a lower incentive ($5 Amazon gift card) (Bowen et al., 2008) (Figure 2), screening out participants who missed attention checks and participants with mismatched state and zip code, refreshing the survey link daily to prevent link sharing, restricting access to the survey to daytime hours and IP addresses registered within the United States, and using the Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA), a tool that prevents automated (bot) completion of the survey (Dewitt et al., 2018). CAPTCHA requires evidence of human presence to reach a website, often by requiring the user to select relevant photos from a compilation of images or to type text into a text box. In addition, participants who had Facebook accounts were required to authenticate using Facebook single sign-on, and we screened out participants who reported that they had learned about the study through any method other than “Facebook” or “Instagram.”

Social Media Fraud Detection
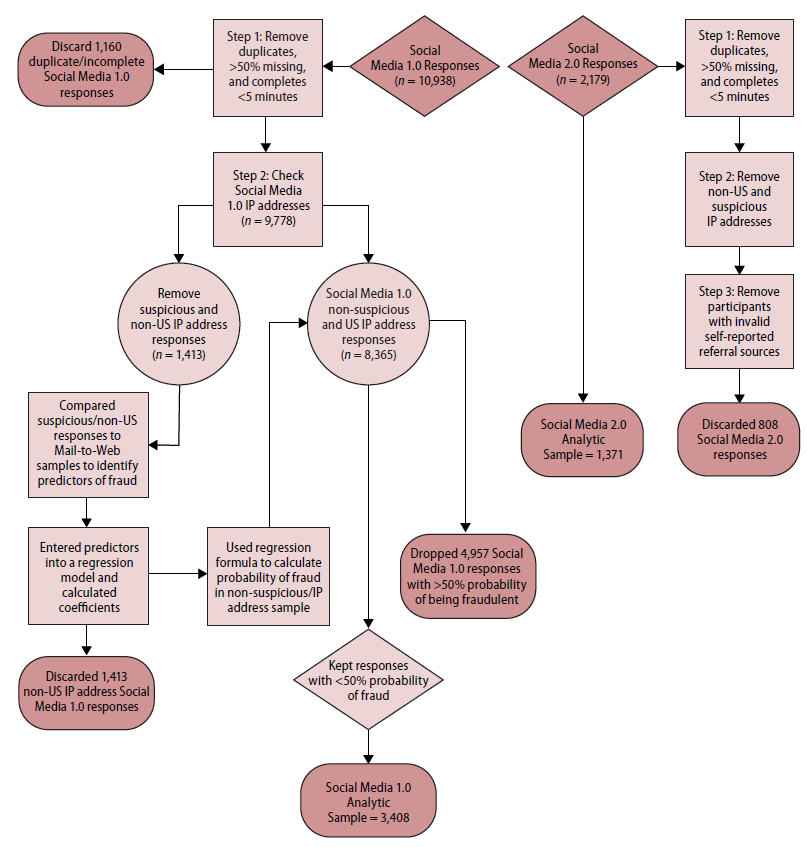
After completing data collection, fraud detection methods for both samples included identifying duplicates using a combination of e-mail address (Bowen et al., 2008), timestamps, IP addresses, and identical responses. We also removed responses with 50 percent or more missing responses, excluded IP addresses outside of the United States and those known to be fraudulent or suspicious (using an online database), and excluded survey completions of 5 minutes or less (mean completion time was 20 minutes).
For SM 2.0, we also excluded respondents who answered “Facebook” or “Instagram” as their referral source but did not access the survey from either platform. After completing fraud detection procedures, 8,365 SM 1.0 responses (14 percent decrease in sample size) and 1,371 SM 2.0 responses (37 percent decrease in sample size) remained.
Fraud Model
Because (1) fraud detection methods only resulted in a small decrease in sample size for SM 1.0, (2) we found evidence that the survey’s URL had been shared on social media, and through manual examination of the data, (3) we noticed patterns of unusual and contradictory responses in the data, we remained concerned about potential fraud in the sample. We created a fraud model (described in the Analysis section) to identify additional fraudulent responses.
Variables
Variables for Fraud Model
Outcome Variable
Fraud: To develop the fraud model, we first identified survey responses that distinguished between valid (Mail-to-Web) and invalid (SM 1.0 respondents with non-US IP addresses) respondents. Since participants were required to be US residents, we deemed SM 1.0 respondents with non-US IP addresses fraudulent (fraud = 1). Because ABS samples are highly reliable, we deemed the Mail-to-Web responses valid (fraud = 0).
Probability of fraud: Continuous probability of fraud was also the outcome of the fraud model.
Predictor Variables
To identify the predictor variables for the fraud model, we started with the full list of variables assessed by the survey, then excluded demographics (because these characteristics tend to vary by mode of data collection (Dewitt et al., 2018)) and questions used to estimate cannabis use prevalence (to avoid biasing estimates used to validate the combined dataset). Using bivariate comparisons, we identified variables that distinguished between fraudulent and nonfraudulent responses. Then, we narrowed down this list to responses that met one or more relevant characteristics from Baker and Downes-LeGuin’s list of suspicious survey responses (Hilbert & Redmiles, 1999): selection of all responses for a multiple-choice question, selection of unlikely (“bogus”) or low probability answers, internally inconsistent responses, and “straight lining” (selecting one answer for all items) in grids (Dewitt et al., 2018). We excluded the following variables that did not meet any of these criteria: method of accessing the internet, social media use, mental health, and voting frequency. We also excluded variables with cell sizes smaller than 10 and/or variables for which 25 percent or fewer participants responded to the item because these items would result in model instability and/or a large number of missing responses for the model. Based on these criteria, we also excluded driving a car within three hours of getting high, usual method of obtaining cannabis, going to work within three hours of getting high, and using cannabis while at work.
The resulting variables included in the model were:
-
Military health insurance: Using military, CHAMPUS, TriCare, or the VA insurance for most medical care (1) (as opposed to Medicare, Medicaid, Indian Health Service, other, none, or “don’t know”; 0); this is a low probability response (Berchick et al., 2018).
-
Parent or guardian of a child (or children) of all ages: Endorsing being a guardian of child(ren) ages 12 or younger, 13 to 17, and 18 to 21 (1) versus two or fewer of these options (0); this response represents selection of all items in a multiple-choice question.
-
Self-employed: Endorsing self-employed (1) occupational status, as opposed to employed for wages, out of work, a homemaker, a student, retired, unable to work, or prefer not to answer (0); this is a low probability response (Hipple & Hammond, 2016).
-
High while taking survey (1), as opposed to not high (0); this is a low probability response.
-
Accessing survey through “a mailed letter someone gave to me” (1), which was not possible (low probability answer). The other response options were feasible: via a mailed letter sent to my home, a Facebook ad or sponsored NewsFeed story, sent to me by Facebook or another way, or another way (0).
-
Types of tobacco used in the past 30 days: A count of the number of products endorsed from the following: (1) cigarettes; (2) vapes; (3) cigars; (4) chewing tobacco, snuff, dip, or snus; (5) and hookah or waterpipe); this pattern reflects selection of all responses for a multiple-choice question.
-
Marijuana consumption modes in the past 30 days: A count of the following products: (1) edible marijuana; (2) personal vaporizer, e-joint, or volcano to smoke dry marijuana plant matter (such as leaves, buds, or flower); (3) personal vaporizer, e-joint, or volcano to smoke marijuana as hash, hash water, hash oil, or marijuana concentrates (dabs); and (4) smoke a blunt (marijuana or hash in a cigar or blunt wrap); this response represents selection of all responses for a multiple-choice question.
-
Daily versus occasional cannabis use: Rating daily cannabis use as better (1), safer (1), and more morally acceptable or correct (1) rather than vice versa (0 for all comparison groups), which are inconsistent responses.
-
Recreational versus medical use: Rating recreational cannabis use as better (1), safer (1), and more morally acceptable or correct (1) than medical cannabis, which represent inconsistent responses.
-
Legal to drive high: Reporting “yes” (1) (versus “no” or “don’t know”; 0) to whether it is legal to drive after using marijuana in the participant’s state; this is a low probability response.
-
Cannabis more harmful to society than alcohol: Selecting marijuana (1) as more harmful to society than alcohol if widely available, as opposed to rating alcohol as more harmful, the two substances as equally harmful, or don’t know (0). Based on the existing literature (Allen et al., 2017), these responses represent low probability and/or inconsistent answers.
Weighting Variables
The following variables were used to create weights that calibrated the subsamples of the NCCS:
-
Gender was defined as female, male, or other category.
-
Age was self-reported number of years old.
-
Race/ethnicity was coded as non-Hispanic white, non-Hispanic Black/African American, Hispanic, or non-Hispanic other race.
-
Education was coded as never attended school or only kindergarten, grades 1–8, grades 9–11, grade 12 (high school graduate) or GED, some college but no degree, associates degree (AA, AS), college graduate (BA, BS), some graduate or professional school, or graduate or professional degree.
-
State cannabis legal status was defined by participant’s self-reported state of residence, according to the following categories: recreational and medical cannabis legal, medical cannabis only legal, or neither.
-
Political philosophy response options included very conservative, somewhat conservative, moderate—neither liberal nor conservative, somewhat liberal, very liberal, or none of the above.
-
Internet access was measured as reporting dial-up service, DSL service, cable modem service, fiber optic service, mobile broadband plan, satellite, or some other service (1) versus no internet service (0).
-
Social media use was categorized as responding “yes” to the question, “Are you on social media, such as Facebook, Instagram or Twitter” (1) versus responding “no” (0).
-
Dwelling type: This information was obtained from the CDS, and we defined the variable as apartment, multifamily, or high-rise building (1) versus a single-family home (0).
-
Rural postal delivery route: This information was obtained from the CDS, and the variable was defined as a rural postal delivery route (1) versus all other types of delivery routes (0).
Validation Variables
The following variables were used to validate the sample and its estimates of cannabis use:
-
Ever cannabis use was assessed by the question, “Have you ever, even once, used marijuana in any form?” We assigned participants who reported having ever used cannabis a value of 1 for this variable and all others a value of 0.
-
Current cannabis use was defined as reporting last using marijuana “within the past 30 days” (1); all other participants were noncurrent users (0).
Analyses
All analyses were conducted in Stata 16.0 (https://www.stata.com/).
Fraud Model Development
First, we used chi-square analyses, t tests, and ANOVAs to identify differences in survey responses between the Mail to Web (fraud = 0) and SM 1.0 responses with non-US IP addresses (fraud = 1) (Dewitt et al., 2018). Next, we regressed fraud on our predictor variables. We used logistic regression (as opposed to further bivariate comparisons) because it enabled us to combine responses to multiple questions to produce a probability of fraud for each individual in the sample. The logistic regression model was ln(p(fraud)1−p(fraud))=β0+m∑i=1BiXi, where m is equal to the number of predictor variables in the model. We used the resulting model to obtain beta values for each of the predictor variables in the model. We refer to this equation as the fraud prediction formula. Once we had calculated the formula, we dropped the non-US IP address SM 1.0 responses from the sample.
The next step was to use the fraud prediction formula to identify additional fraudulent responses among the US IP address SM 1.0 responses. We used the formula to calculate the probability of fraud for these respondents by multiplying the value of each beta coefficient in the formula by each participant’s value for X for all predictor variables in the model and summing these values to calculate y, which was equal to for each respondent. After calculating y, we solved for which is the probability that each SM 1.0 response is fraudulent. We set a cutoff of 50 percent or greater probability of fraud for dropping participants from this sample.
Sensitivity Analyses
To ensure that 50 percent was the correct cutoff value, we conducted sensitivity analyses using values of 33, 50, and 66 percent or greater probability of fraud as cutoff values for SM 1.0 participants with US IP addresses. Using the same predictor variables included in the fraud prediction formula, we compared the characteristics of each of the samples obtained from the three cutoff values to the characteristics of the Mail-to-Web sample (valid) and non-US IP address SM 1.0 responses (fraudulent) to identify the best cutoff value.
Weighting
After choosing a cutoff value for fraud, we used weights to calibrate all of the NCCS subsamples to each other and the resulting pooled sample to the US population. The weighting procedures we used were a modified version of an existing approach applied to an Oregon cannabis survey (Kott, 2019). Our weighting procedures also represent an updated and final version of the preliminary weighting scheme used on the NCCS before the fraud model was developed (Dever, 2018). Generally, our approach involved a descriptive comparison of demographic and geographic characteristics and predictors of cannabis use across the probability and nonprobability samples, sample matching using the R MatchIt package, multiple propensity score models, comparing the demographics of the social media and ABS samples across these models, and comparing the prevalence of several measures of cannabis use and opinions for the NCCS and previous surveys (Dever, 2018; Kott, 2019). The final weighting scheme was based on the differences that we observed between the mail and social media samples, the similarities we observed between the Mail-to-Web and social media samples, and the finding that political philosophy was a better predictor of attitudes toward cannabis use than cannabis use itself (Kott, 2019). We also used the SUDAAN 11 (https://sudaansupport.rti.org/) WTADJX procedure for calibration.
Validation
After determining the cutoff for fraud, dropping all remaining fraudulent SM 1.0 responses, and weighting the pooled dataset, we validated the sample (Dever, 2018) by comparing NCCS estimates for ever and current cannabis use with similar estimates in the published literature (Dever, 2018), specifically estimates obtained from the 2016 NSDUH (Center for Behavioral Health Statistics and Quality, 2017), the 2017 Yahoo News/Marist Poll (Marist Poll, 2017), and the 2016 Gallup Poll (McCarthy, 2016). We attempted to locate social media or online surveys of cannabis use but were unable to locate any.
Results
Bivariate Results
For bivariate comparisons of SM 1.0 respondents with non-US IP addresses and Mail-to-Web respondents, non-US IP address SM 1.0 respondents were significantly more likely than Mail-to-Web respondents to report military health insurance, having children in all three age groups captured by the survey, being self-employed, being high while taking the survey, reporting receiving a mailed survey from someone else, number of types of tobacco used, number of modes of cannabis used, being more accepting of daily cannabis use than occasional use, being more accepting of recreational cannabis use than medical use, believing it is legal to drive high, and believing that cannabis is more harmful to society than alcohol (P < 0.001; Table 2).
Fraud Prediction Formula
Regressing the fraud variable on our predictor variables yielded the following fraud prediction formula: = β0 + 23.97(Military insurance) + 301.64(Children of all ages)+ 14.37(Self-employed) + 1651.79(High) + 382.87(Letter from someone else) + 9.00(Number of types of tobacco) + 4.37(Number of modes of cannabis) + 20.37(Daily cannabis use better than occasional) + 15.38(Daily cannabis use safer than occasional) + 11.72(Daily cannabis use more right than occasional) + 36.58(Recreational cannabis use better than medical) + 7.37(Medical cannabis use more dangerous than recreational) + 14.17(Recreational cannabis use more right than medical) + 373.09 (Legal to drive high) + 12.38(Cannabis more harmful than alcohol). Multiplying the values of X by the beta values from the above equation for each SM 1.0 participant with a US IP address and solving for we identified 6,370 participants with a 50 percent or higher probability of fraud.
Sensitivity Analyses
The sensitivity analysis confirmed our use of the 50 percent cutoff. Using the 33 percent cutoff, the nonfraudulent sample significantly differed from the fraudulent sample for all variables and from the Mail-to-Web sample for eight variables (Table A.1 in the Appendix). Using the 50 and 66 percent cutoff values, the nonfraudulent sample significantly differed from the fraudulent sample for all variables and from the Mail-to-Web sample for five variables (Tables A.2 and A.3). Because the samples resulting from 50 and 66 percent cutoff values performed equally well in resembling the Mail-to-Web sample and differing from the fraudulent sample, and the 66 percent cutoff resulted in a much smaller sample size (2,650), we chose to use the 50 percent cutoff (3,408) to preserve statistical power.
Survey Weights
The weighting scheme incorporated six characteristics: gender, age, race/ ethnicity, education, cannabis legal status, and political philosophy (Ridenhour & Kott, 2018). First, we adjusted for differential nonresponse across sampling strata, dwelling type, and rural postal delivery route in the Mail 1.1 sample (Ridenhour & Kott, 2018). Then, we used the SUDAAN 11 WTADJX procedure to calibrate the samples to population estimates and each other (Kott, 2019; Ridenhour & Kott, 2018). We used gender, age, race/ethnicity, and education to calibrate Mail 1.1 respondents to continental US population totals from the American Community Survey (ACS) (United States Census Bureau, 2021). We then used cannabis legal environment, age, education, gender, and political philosophy to calibrate the Mail-to-Web respondents to Mail 1.1 participants who reported having internet access and the SM 1.0 and SM 2.0 samples to Mail-to-Web participants who reported being on social media.
We assumed that the weighted groups of Mail 1.1 respondents and Mail-to-Web respondents with social media, SM 1.0 respondents, and SM 2.0 respondents represented the same subpopulation and that the weighted groups of Mail 1.1 respondents with internet but without social media and Mail-to-Web respondents without social media represented the same subpopulation. We then computed effective cohort sample sizes for each of these groups (sample size divided by unequal weighting effect for each group). We combined respondents with internet but without social media (two groups) and respondents with social media (four groups), using effective cohort sample sizes for both combinations, resulting in one group that could be analyzed as the population of interest (Ridenhour & Kott, 2018).
Validating the Sample
To validate the sample, we compared weighted estimates for cannabis use in the NCCS to the results of other publicly available surveys of adults 18 and over in the United States (Dever, 2018) (Table 3).
NSDUH relies on a stratified, multistage area probability sample and is conducted via in-person interviews (Center for Behavioral Health Statistics and Quality, 2017), while the Yahoo! and Gallup surveys included random samples of landline and mobile phones and were conducted by phone (Marist Poll, 2017; McCarthy, 2016). Ever use was higher in the NCCS sample and subsamples compared with the other data sources, but these values approached those found in the Yahoo News survey. For current use, NCCS estimates fell between the estimates obtained from probability and nonprobability samples.
Discussion
This analysis used a fraud regression model, in combination with other fraud prevention and detection methods, to identify and eliminate probable fraudulent completes in a social media sample. This analysis also described the weighting and validation methods used for this study.
Several lessons can be gleaned from the data collection and described methods. The first is the importance of the prevention of fraud in social media, which has become increasingly common over time. We had few fraud issues when we included fraud prevention methods in our social media data collection (SM 2.0).
The second lesson is the ability to use patterns of similarities and differences between fraudulent and nonfraudulent responses to clean datasets plagued by fraud. The predictive model of fraud described in this manuscript provides an advantage over bivariate analyses (Dewitt et al., 2018) by using information obtained from several variables to determine fraud, as opposed to examining the variables one at a time. Also, the model calculates fraud as a probability.
Our use of fraud prevention methods and validation increased our confidence in the quality and accuracy of the resulting dataset. The estimates obtained from the combined ABS and social media sample produced cannabis prevalence estimates similar to but higher than those of other surveys in the field at the time. Because of differences between the surveys, most notably in data collection methods, it is appropriate for the results from the NCCS to resemble, but not exactly match, those obtained from these other surveys (Bowyer & Rogowski, 2017; Dillman, 2006; Keeter, 2015; Supple et al., 1999). NSDUH uses in-person interviews, and Yahoo! and Gallup used telephone surveys to collect data. Responses tend to differ by survey mode due to social desirability and varying perceptions of anonymity (Supple et al., 1999). In fact, research suggests that substance users are unrepresented in samples obtained via data collection methods (Johnson, 2014) such as interviews (Lyons Reardon et al., 2003) and landline surveys (Delnevo et al., 2008). In addition, NCCS did not use the same item as NSDUH to assess ever (lifetime) use of cannabis; NSDUH asks, “Have you ever, even once, used marijuana or hashish?” (Center for Behavioral Health Statistics and Quality, 2015) Our use of quotas to sample participants from different cannabis legal environments likely also affected the prevalence of cannabis use in the study.
Limitations
This study has several limitations that should inform the interpretation of its results. The fraud model we created relied on several assumptions: (1) all non-US IP address SM 1.0 responses were fraudulent (fraud = 1) and all Mail-to-Web responses were not (fraud = 0); (2) all variables that differed significantly (P < 0.05) between non-US IP address SM 1.0 responses and Mail-to-Web responses could be used to predict fraudulent responses among SM 1.0 participants with US IP addresses; and (3) the likelihood of a nonfraudulent complete scoring a high probability of fraud was very low. It is possible that one or more of these assumptions is incorrect, but we based these procedures on extensive analyses of the data. Another limitation is that fraud prevention and detection procedures have improved greatly since the NCCS. However, widespread fraud still occurs, and methods of committing social media fraud are constantly evolving to adapt to improved measures of fraud prevention and detection. The process for developing a fraud model described in this manuscript can be applied to existing and future data collections despite changes in fraud and fraud prevention technology.
Conclusion
This paper outlines fraud prevention and detection measures that can be applied to future data collections. In addition, this manuscript outlines a fraud detection model that can be applied to existing social media datasets riddled with fraud. This manuscript also outlines methods of combining probability and nonprobability samples using weights. Overall, this analysis provides methods for resolving common issues encountered during and after data collection.
Acknowledgments
The authors would like to thank Phil Kott, Jill Dever, Kian Kamyab, Josh Goetz, Jessica Pikowski, Carla Bann, and Gary Zarkin. This research was funded by RTI International.