Introduction
Despite a flurry of headlines regarding the arrival of technologies involving various forms of artificial intelligence (AI), public discourse has not focused extensively on ethical and logistical questions about human interactions with the range of new entities that likely will emerge in the coming decades, as Boyle (2024) notes in The Line: AI and the Future of Personhood. Commentators have celebrated, bemoaned, and speculated about the arrival of AI, and recent public opinion research suggests widespread popular concern about the adoption of AI tools (Rainie & Anderson, 2025). Some editorials and review papers to date have focused on emerging technical issues specific to topical domains without consideration of what kinds of questions could and should be asked about human choices, agency, and opportunities. In other cases, we can find broad philosophical exploration about the nature of humans and technology that lacks specific suggestions for steps that organizational decision-makers can take. We need formalized research agendas in many areas, including education, health, creative expression, and governance.
Generating and analyzing informative and coherent evidence to address concrete questions stemming from public commentators’ observations and concerns remains a task for scientists to address. Researchers have begun to ask relevant questions, such as whether we should include AI applications in organizational charts (Burton et al., 2024), how generative AI applications can enhance organizational efficiency (Obrenovic et al., 2025), and the extent to which AI applications can improve patient outcomes in health care (Gala et al., 2024). We need empirical evidence comparing different technologies and approaches and assessing both intended effects and unintended consequences. By presenting both substantive findings and methodological lessons learned here, we illustrate how human and AI-enabled processes together can inform agenda-setting in emerging areas of inquiry, and we spotlight key questions we should be asking about roles for humans amidst societal changes involving AI. Research to generate such evidence will require we continue to articulate and assess answerable questions about technologies that are not yet altogether here and human capacities and preferences, which also can change over time.
How to Build a Research Agenda Collaboratively
Efforts to address possibilities for human interaction with AI applications can benefit from multiparty collaboration, particularly when researchers seek to establish shared lines of inquiry. Such collaboration offers promising diversity and greater volume of ideas but also introduces challenges. Collaboration is not always necessary for adequate task completion, as individual researchers or organizations can make substantial progress on their own in many instances. Collaboration also can offer an illusion of progress if not aligned with organizational goals and well-organized (Antikainen et al., 2010; Gardner, 2005; Schmutz et al., 2024). Agreement regarding participant motives and goals can help sustain collaborative efforts beyond a meeting or two, ensuring momentum after initial meetings and setting groundwork for concrete outcomes. Additionally, an important aspect of team collaboration performance is the interdependence of tasks and the group’s sense of distinctiveness and shared identity (Gundlach et al., 2006). Seeking such group identity among researchers and practitioners can encourage continued efforts to answer questions that matter by facilitating forums for discussion and inquiry.
We convened relevant professionals to generate and refine questions about human interactions with AI tools and to discuss research needs associated with developments in education and workforce training, health care, creative expression professions, and governance. In analyzing the results of the collaborative discussions that ensued, we also explored ways groups of people can work together to use AI tools to make sense of human brainstorming inputs. In other words, we were able to assess some approaches to generating and developing questions about human interaction with AI. What we report here is both a summary of those efforts and reflections on implications for future research.
An Agenda-Setting Convening to Ask Questions about Human Interaction with AI
We designed and implemented a network-building and agenda-generating effort in fall 2025. In September 2025, approximately 450 researchers, practitioners, AI industry experts, leaders from eight universities in North Carolina (Duke University, Elon University, Fayetteville State University, North Carolina A&T State University, North Carolina Central University, North Carolina State University, the University of North Carolina at Chapel Hill, and the University of North Carolina at Greensboro), the National Humanities Center, and a variety of professional organizations participated either online or in-person at a summit organized by RTI International and Elon University. In the afternoon, we invited the 178 in-person attendees to participate in one of 23 in-person discussion groups, each moderated by a facilitator with social science research experience and group interviewing skills. Each group primarily had an opportunity to focus on one of four topic areas: education, workforce, and labor; human agency and creativity; mental and physical health and well-being; and governance and democracy. Participants indicated the topic they hoped to discuss before the convening, and all participants joined a discussion in which they had expressed interest.
Participants discussed “the most important questions we should be asking and addressing about the role of humans in this subject area as AI systems continue to evolve,” guided by moderators who used a discussion guide developed by conference organizers in advance. Moderators also invited participants to discuss who is well-positioned to examine these questions and what resources are needed to pursue answers to key questions. Groups submitted answers using a shared electronic form that recorded text responses in fields in an Excel file. At the day-long event, organizers used AI tools in combination with human discussion (as described in a later section of this article) to generate an initial summary of ideas, which was shared with the entire group of in-person attendees within an hour of completion of the discussions. After the event, organizers invited all participants to consider joining one of multiple teams of analysts to use tools and group discussion to summarize key questions from the convening. What follows is a description of the analysis efforts conducted by four analysis teams. Reflections from each team on the process of distilling insights using various approaches also appear in Appendix B.
Results from Four Approaches to Synthesis
Four human teams comprising participants from the convening used different tools and processes to generate final sets of research questions based on convening input. All four teams had access to the same file, which contained text inputs from the 23 groups. We present the final set of questions from each of the four analysis teams after a brief description of each unique analytic approach. Table 1 summarizes different analytic approaches. Additional details on analysis differences and team observations appear in Appendix B.
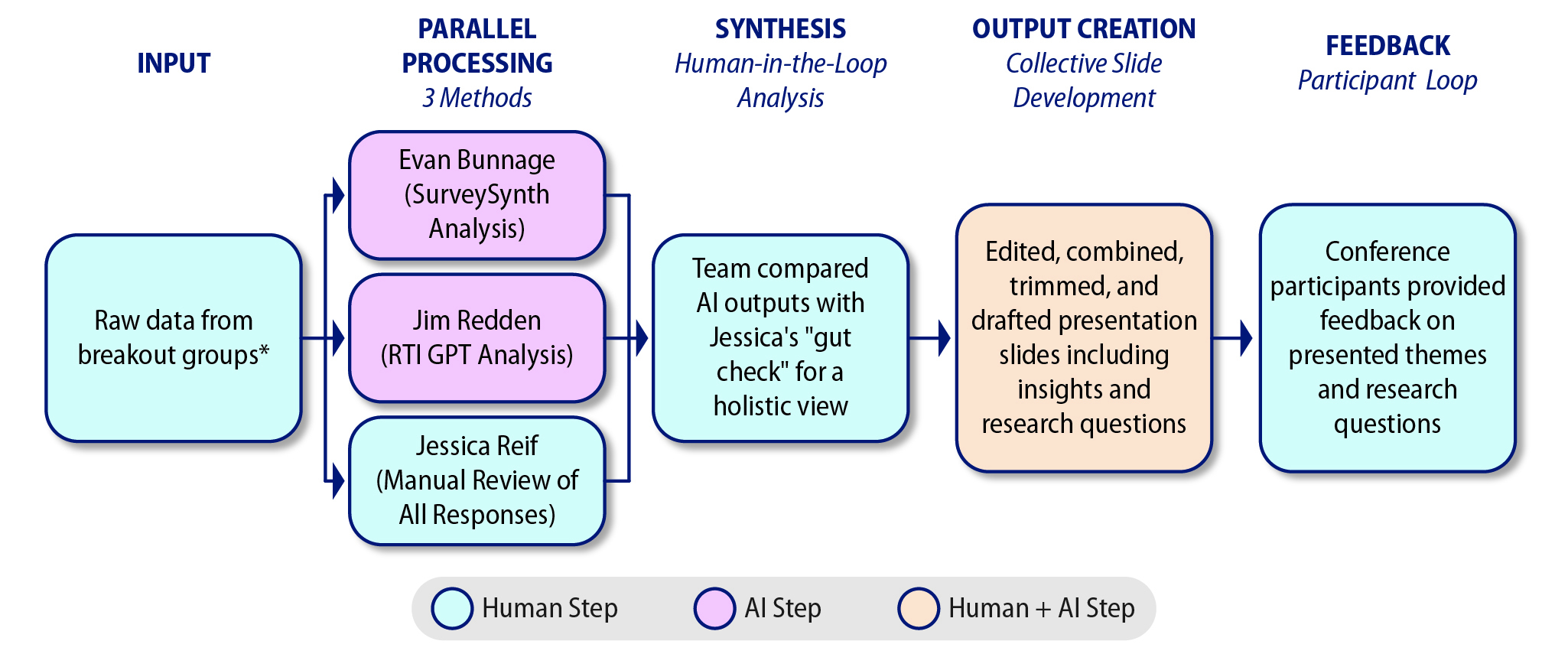
1. Rapid Processing and Follow-up Using SurveySynth and RTI GPT (Jim Redden, Evan Bunnage, and Jessica Reif)
Brief Description of Analysis Approach
The team used a combination of human judgment and AI tools developed for internal use at RTI to synthesize rapidly, giving an initial presentation back to participants within an hour of the discussion exercise concluding. The approach used parallel processing with multiple validation checkpoints. When group discussions concluded on the day of the event, three team members downloaded submitted data and simultaneously initiated three distinct work streams. One researcher employed SurveySynth, an RTI-developed AI tool designed to qualitatively code and synthesize free-text survey responses. A second researcher used RTI GPT, the organization’s internal large language model (LLM) tool based on OpenAI’s GPT-4o and GPT-4o mini, applying a detailed prompt to synthesize the breakout responses. In parallel, a third researcher conducted a complete human review of the entire group input dataset, reading through all submitted responses without AI assistance.
Identified Questions: Education, Workforce, and Labor
-
What foundational and advanced human skills—such as soft skills, critical thinking, and creativity—should educators and employers prioritize to ensure humans thrive alongside AI in the future workforce?
-
How can AI-enabled personalization in education and workforce systems balance innovation and fairness to ensure equitable access and avoid exacerbating societal inequalities?
-
What ethical frameworks, regulatory structures, and institutional collaborations are essential to ensure responsible, transparent, and inclusive adoption of AI across education and workforce sectors?
Identified Questions: Mental and Physical Health and Well-Being
-
How can we develop AI tools in health care that prioritize transparency, accountability, and trustworthiness while ensuring equitable access for underserved populations?
-
What strategies and partnerships are required to train health care professionals, patients, and communities in responsible and effective AI integration, fostering collaboration across diverse expertise and perspectives?
-
How can AI systems balance efficiency and human-centric care outcomes while minimizing environmental costs and resisting profit-driven incentives in health care innovation?
Identified Questions: Human Agency and Creativity
-
How can we preserve human agency and ensure equitable representation in creative and knowledge fields as AI becomes an active collaborator in cultural and creative pursuits?
-
What policies and frameworks are necessary to address intellectual property in AI-human collaborations, protect human creativity, and prevent cultural commodification?
-
How do we redefine the relationship between productivity and creativity in a society increasingly shaped by AI, while mitigating environmental and societal harms?
Identified Questions: Governance and Democracy
-
What regulatory frameworks at local, national, and global levels can balance the need for AI transparency and accountability with fostering innovation across diverse sectors?
-
How can affected communities, civil society organizations, and governing bodies meaningfully participate in AI-related governance processes to ensure equity, oversight, and ethical decision-making?
-
What strategies can promote civic knowledge, media literacy, and democratic engagement in the age of increasingly fragmented, AI-influenced information landscapes?
2. A Rubric Approach Using GPT-5 Emphasizing Theme Frequency (Maria Gallardo-Williams, Rob Chew, and Ray Levy)
Brief Description of Analysis Approach
The team’s approach involved developing a rubric grounded in established research design principles and then instructing GPT-5 (model alias:gpt-5-2025-08-07) to score each research question generated during the workshop using this rubric. The rubric or framework draws from leading methodological sources, including Creswell and Creswell (2017), Booth (2016), and the FINER (Cummings et al., 2013) and SMART (Adeoye & Adong, 2023) evaluation models. These foundations emphasize that a high-quality research question should be clear, researchable, significant, complex, and feasible while maintaining ethical integrity. The team’s evaluation system operationalized these qualities into seven measurable criteria: (1) clarity and focus, (2) ability to be researched, (3) significance and relevance, (4) theoretical or practical contribution, (5) complexity and depth, (6) feasibility and scope, and (7) ethical soundness. The team used the LLM to score the questions from the workshop discussions on a 1 to 5 scale for each criterion, and the two highest-scoring questions per topic were selected to represent each domain. Human analysts were responsible for developing the rubric and prompts, and the LLM collated, scored, and evaluated the research questions.
A distinctive feature of the team’s approach is the inclusion of a frequency dimension as a proxy for expressed participant interest and perceived importance. Because workshop participants often generated overlapping or near-duplicate questions, frequency counts captured how often similar ideas emerged across breakout groups. The team also used frequency as a tiebreaker consideration when multiple questions received identical high scores.
Identified Questions: Education, Workforce, and Labor
-
When and how should humans remain “in the loop” to detect and correct AI errors in education and work?
-
What strategies ensure equity, infrastructure, and access for all communities in AI-enabled education?
Identified Questions: Mental and Physical Health and Well-Being
-
What AI prompt best practices are most impactful for reducing bias in health research?
-
How can we ensure data protection and privacy and assess the trustworthiness of AI systems?
Identified Questions: Human Agency and Creativity
-
How do we avoid deepening inequalities caused by AI?
-
Who holds creative license or intellectual property rights over AI-generated work—the AI, the prompter, or others?
Identified Questions: Governance and Democracy
-
How do we ensure that automated decision-making is fair, equitable, and just and that it advances human flourishing?
-
How do we implement AI governance that ensures a human-centered, ethical focus at every stage—idea, design, development, and deployment?
3. Iterative Development of Theses and Questions Aided by ChatGPT Summary (Matthew Strobl, Heather Griffiths, Rachel Page, and Haley Hickman)
Brief Description of Analysis Approach
To analyze the group input data, the team used ChatGPT Plus 5.0 in conjunction with Google Meet to facilitate collaborative discussion and review among team members. Human analysts played an active role throughout the process, guiding the prompts, refining inputs, and interpreting the outputs. The team instructed the tool not to offer praise for our work in a subsequent prompt to test tone and framing. When ChatGPT’s responses stalled or failed to complete, the team removed or simplified the more-complex requests to maintain progress. At times, when the tool prompted for a response to continue or update its analysis, they intentionally paused to refine instructions and approach. Human feedback occurred organically through team dialogue and is therefore difficult to fully capture. They also re-prompted ChatGPT to take on a skeptic’s role to challenge and assess its own outputs more critically. When this approach caused repeated stalling, they adjusted the prompt to position it as a neutral judge instead, offering more-detailed guidance on how to analyze the data. Ultimately, human analysts exercised judgment at each stage to determine which iterations produced the most-accurate, most-balanced, and most-insightful analysis.
Identified Theses and Questions: Education, Workforce, and Labor
Thesis 1: The degree of alignment between educational curricula and employer-defined AI competencies predicts the distribution of re-skilling opportunities.
- Relevant questions: How closely do education and training programs map to employer-identified AI skill needs? What groups or regions show the largest gaps between available training and workforce demand? What mechanisms (curriculum audits, employer feedback loops) improve skill alignment?
Thesis 2: The presence of structured partnerships among education systems, employers, and public agencies influences implementation of AI-related training programs.
- Relevant questions: What forms of cross-sector partnerships are associated with faster adoption of AI training modules? How do funding, governance, or shared infrastructure arrangements affect implementation scope? What indicators show successful program uptake across sectors?
Identified Theses and Questions: Mental and Physical Health and Well-Being
Thesis 1: The adoption of AI-supported triage or scheduling tools in community health centers changes referral completion and care coordination patterns.
- Relevant questions: How do AI scheduling or triage tools affect patient referral completion rates and wait times? What differences appear between centers with and without AI-enabled coordination? How do staff workflows or communication practices change after implementation?
Thesis 2: Governance transparency in AI-driven health platforms affects data-sharing frequency between institutions.
- Relevant questions: Which governance practices (e.g., consent visibility, audit reporting) are linked to higher data-sharing frequency? How do institutions evaluate trade-offs between transparency, privacy, and efficiency? What evidence links governance changes to shifts in data exchange activity?
Identified Theses and Questions: Human Agency and Creativity
Thesis 1: The level of human review required in AI-assisted content production affects decision turnaround and attribution practices.
- Relevant questions: How does the number or type of human review steps correlate with output speed and approval rates? What documentation practices assign authorship in AI-assisted outputs? How do patterns differ across organizational or sectoral contexts?
Thesis 2: Institutional rules defining AI authorship determine the approval chain and accountability structure in creative outputs.
- Relevant questions: What policies outline when AI-generated material requires human sign-off? How do institutions document accountability for AI-assisted decisions? What variations exist in governance across industries using AI in creative or analytical work?
Identified Theses and Questions: Governance and Democracy
Thesis 1: The proportion of civil society representation in AI oversight bodies correlates with the perceived fairness of governance outcomes.
- Relevant questions: What percentage of governance seats are occupied by civil society actors? How do participants assess fairness and responsiveness of oversight decisions? Which participatory mechanisms align with perceptions of procedural fairness?
Thesis 2: The communication framing of AI regulation affects citizen perceptions of institutional legitimacy.
- Identified questions: How do alternative framings (risk-based, rights-based, innovation-based) influence perceived legitimacy? What messaging strategies improve understanding of regulatory intent and accountability? How do demographic or ideological factors mediate public responses to AI policy communication?
4. Human-Guided Use of Python Scripts, Claude 3.5 Sonnet, and Microsoft Copilot to Analyze Data Filtering and Extraction (Tony Kipkemboi, Jon Accarrino, Schuyler DeBree, and Selena Monk)
Brief Description of Analysis Approach
Each of four analysts took responsibility for one of the topical themes and selected a strategy for analysis.
To analyze the data for the Education, Workforce, and Labor track, an analyst used Copilot and Excel in combination with a structured prompt-based approach, first uploading the breakout session notes captured in the Excel file into Copilot and asking for extraction and filtering of all responses tagged under the relevant topic area. Copilot helped identify and synthesize key themes across multiple discussion summaries when asked to generate research questions. The analyst then determined which insights were most representative of the group’s concerns.
To analyze the Mental and Physical Health and Well-Being track, one analyst used a systematic iterative approach using Anthropic’s Claude, an AI assistant, combined with manual review of the data, first extracting all group responses from this topic area and asking Claude to identify recurring themes. The analyst iteratively refined analysis by asking follow-up questions about specific tensions, such as, “How do the discussions characterize the tension between profit motivation and patient welfare?”
To analyze the data for the Human Agency and Creativity track, one analyst combined Claude with Python-based data analysis, first uploading the Excel file containing breakout session notes and using Python scripts to filter and extract all four responses tagged under “Human agency and creativity.” The analyst prompted Claude to conduct a comprehensive thematic analysis and then reviewed the thematic synthesis and made critical judgments about which themes were most prevalent and pressing across discussions.
To analyze the Governance and Democracy track, one analyst used Claude (Anthropic, 2025) in combination with a structured comparative framework, isolating the group governance-focused responses and prompting Claude to map the landscape of discussion, identify philosophical positions, and highlight tensions. The human analyst then assessed results and asked Claude to compare different governance philosophies evident in the discussions (e.g., “Should there be standards at all?” vs. calls for comprehensive regulation).
Identified Questions: Education, Workforce, and Labor
-
How can education systems and workforce development programs evolve to prioritize and preserve uniquely human skills, such as critical thinking, empathy, adaptability, and creativity, in an AI-augmented world?
-
What policies, partnerships, and infrastructures are needed to ensure equitable access to AI tools and education while preventing the deepening of digital divides and ensuring that all communities benefit from AI advancements?
Identified Questions: Mental and Physical Health and Well-Being
-
How can health care systems design and implement AI tools that preserve clinician autonomy, critical thinking capacity, and patient-centered care while addressing the tension between profit-driven efficiency metrics and humanistic health outcomes, particularly in ensuring that underrepresented populations and low-resource contexts are meaningfully included in data, design, and deployment decisions?
-
What regulatory frameworks, transparency standards, and collaborative governance structures are needed to ensure AI-augmented health care maintains privacy protections, addresses environmental costs, balances the promise of synthetic data with the need for prospectively collected real-world evidence, and establishes clear accountability when AI-driven decisions lead to patient harm?
Identified Questions: Human Agency and Creativity
-
As AI systems become increasingly integrated into creative and knowledge work, what foundational human capabilities and “starter skills” must be preserved and cultivated to maintain meaningful agency over decision-making and creative processes, and how can we design human-AI partnerships that enhance rather than erode human cognitive autonomy and creative capacity?
-
What governance frameworks, attribution systems, and equity-centered policies are necessary to prevent AI from exacerbating marginalization, commodifying culture, and concentrating creative agency in corporate entities, while ensuring that diverse communities maintain ownership, voice, and fair compensation in the development and outputs of AI-augmented creative work?
Identified Questions: Governance and Democracy
-
What multilevel governance frameworks (local, national, international) are necessary to ensure that AI systems deployed in democratic societies maintain transparency, enable meaningful human oversight of automated decision-making, and build public trust while balancing the rapid pace of technological innovation with the need for enforceable standards that protect human rights and prevent the concentration of power in corporate entities?
-
How can democratic societies cultivate widespread AI literacy and civic knowledge necessary for informed participation in AI governance, ensure that affected communities have meaningful voice in algorithmic decision-making that affects their lives, and preserve the capacity for critical engagement with information in an environment increasingly saturated with AI-generated content and misinformation?
Across all four topical areas, several cross-cutting themes emerged that reflect shared concerns about the future of human–AI interaction. Participants emphasized the need for transparency, equitable access, meaningful human oversight, and reliable governance structures, regardless of domain. Concerns related to infrastructure and the preservation of human agency also emerged. Highlighting these patterns helps place these domain-specific questions within a broader research landscape involving AI and demonstrates the contribution of coordinated inquiry.
Conclusions
A collaborative effort to bring together experts, researchers, and practitioners to identify useful research questions about roles for humans working in various domains amidst AI systems generated a robust research agenda. Nearly 200 in-person participants working in 23 groups contributed sets of questions to guide future research focused on four different topical areas. Small teams of analysts then used a combination of human review and AI-supported tools to organize and assess these inputs, identifying key questions to inform an agenda for future inquiry. That process yielded relevant questions that could offer a foundation for future studies and collaborative projects.
Across teams, recurring dilemmas, opportunities, and questions emerged. These included questions involving comparisons and tradeoffs among different goals for AI use, variations in how people may experience or be affected by AI, and how to optimize human-AI interactions to accomplish tasks. At the same time, different analytic approaches also yielded a diverse array of potential questions reflecting a range of different evaluation criteria, such as the frequency with which ideas appeared across participant groups or the extent to which a topic lent itself to empirical evidence. Across methods, iterative review and human judgment at multiple stages demonstrated value, regardless of the specific tool employed, illustrating how human-in-the-loop design can be useful. That observation has implications for how we could work optimally with AI tools. Explicitly designing and articulating decision-making processes and assigning humans to not only review output but also initiate and consider the questions that guide projects will be important. Planning workflow processes involves choices about how to involve humans. In this way, human actors can integrate AI tools into work while staying in command of key decision-making, as scholars have recently recommended (e.g., “Artificial Intelligence Is Not a Substitute,” 2025).
Organizations involved in education and labor, health care and well-being, creative expression, and governance may identify opportunities to generate evidence to address questions such as those posed here. Rather than solely relying on anecdotal observations about single user experiences with available tools, researchers and practitioners may better inform future decision-making about AI engagement by contributing to and learning from literature that addresses such problems. Learning networks of collaborators, including human teams using AI-assisted tools, could advance available literature but will do so most productively in carefully organized partnerships when party motives are clear and task goals are explicit. Without collaborative efforts to address key research questions about human interactions with AI, organizational missteps, inefficiencies, and ethically problematic consequences are possible. With collective efforts to address key questions, leaders of organizations employing humans should be able to make better choices about when and how to engage AI.
Data Availability Statement
Data availability statement: De-identified data supporting the current study are available from the authors upon reasonable request.
Acknowledgments
The Imagining the Digital Future Center at Elon University and RTI International’s Fellows Program and University Collaborations Office organized The Human Edge: Our Future with Artificial Intelligences, the convening described in this paper, with support from Burroughs Wellcome Fund, the Knight Foundation, and Schmidt Sciences. We are grateful for comments from two anonymous reviewers whose feedback substantially improved the paper, editing support from Claire Korzen, and graphics support from Nunzio Landi.
.jpg)